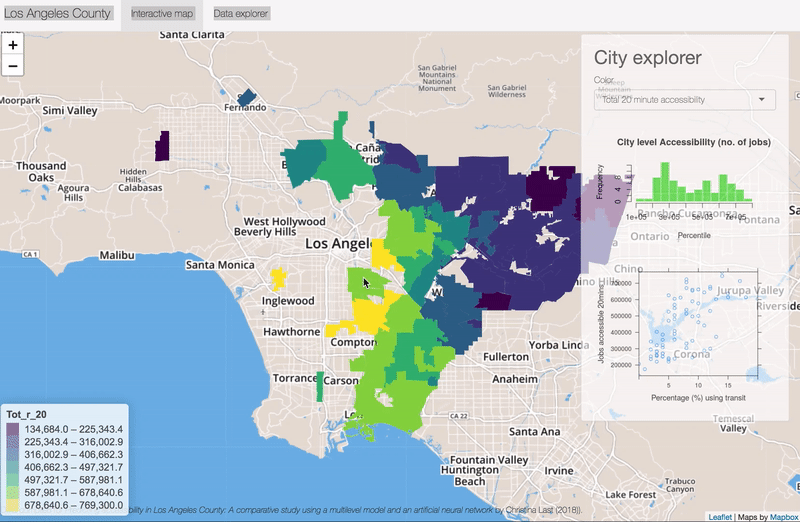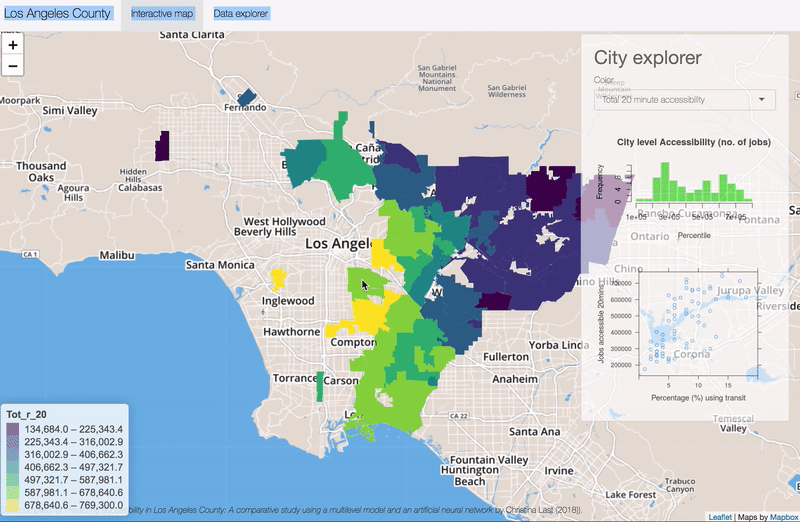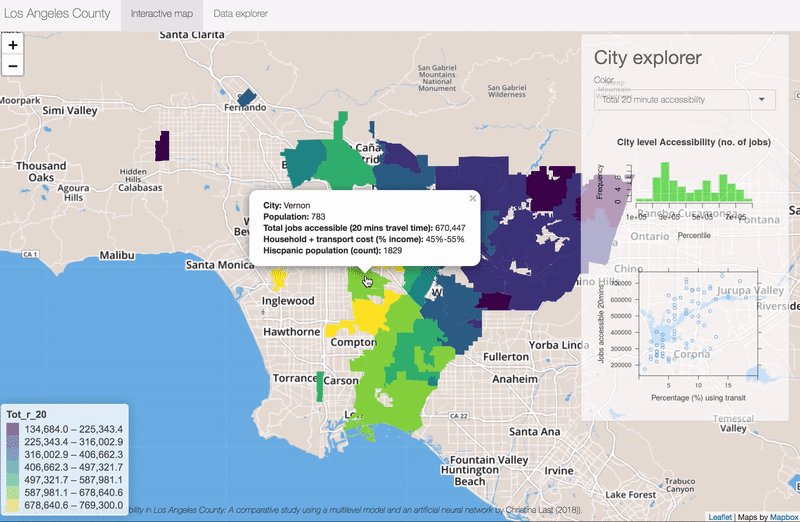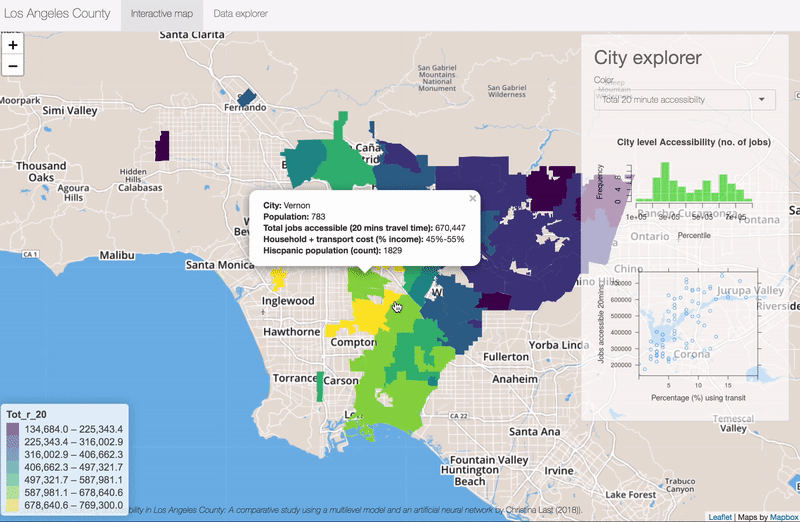
Hide and Seek Robot
Human-Computer interaction for real-world play
CHALLENGE
To investigate the interaction between robots and humans, in urban spaces, similar to looking for a person in a crowded urban environment.
PROJECT
In this project we demonstrate an ability to program on Arduino & Raspberry Pi and communicate between the two systems, program in Python, focusing on OpenCV, and implement deep learning models on the robots to identify faces from purely visual inputs.
To investigate the interaction between robots and humans, in urban spaces, similar to looking for a person in a crowded urban environment.
PROJECT
In this project we demonstrate an ability to program on Arduino & Raspberry Pi and communicate between the two systems, program in Python, focusing on OpenCV, and implement deep learning models on the robots to identify faces from purely visual inputs.

Many similarities of the hide-and-seek game can be found in the interactions between humans, or robots and humans, in urban spaces, similar to looking for a person in a crowded urban environment (Goldhoorn et al. 2014).
It is suggested that the game of hide-and-seek is an ideal domain for studying cognitive functions in robots and it is a basic mechanism for human robot interaction in mobile robotics, because hide-and-seek requires the robot to navigate, search, interact on, and predict actions of the opponent (Johansson and Balkenius 2005).
In this project we demonstrate an ability to program on Arduino & Raspberry Pi and communicate between the two systems, program in Python, focusing on OpenCV, and implement deep learning models on the robots to identify faces from purely visual inputs.
Process 1: Concept
The concept is as follows: the project uses machine learning classification techniques to successfully find a hider by identifying the hider’s face, and move towards the human (the robot’s method of seeking). The visual information captured by the Pi camera is used to train the robot to find a hider.
Through the artistic novelty of human-robot playing we explore the real-world implications in supporting human disaster response teams. For example, one of the many practical applications of this experiment is to find persons; as hide-and-seek could be seen as a simplification of search-and-rescue.
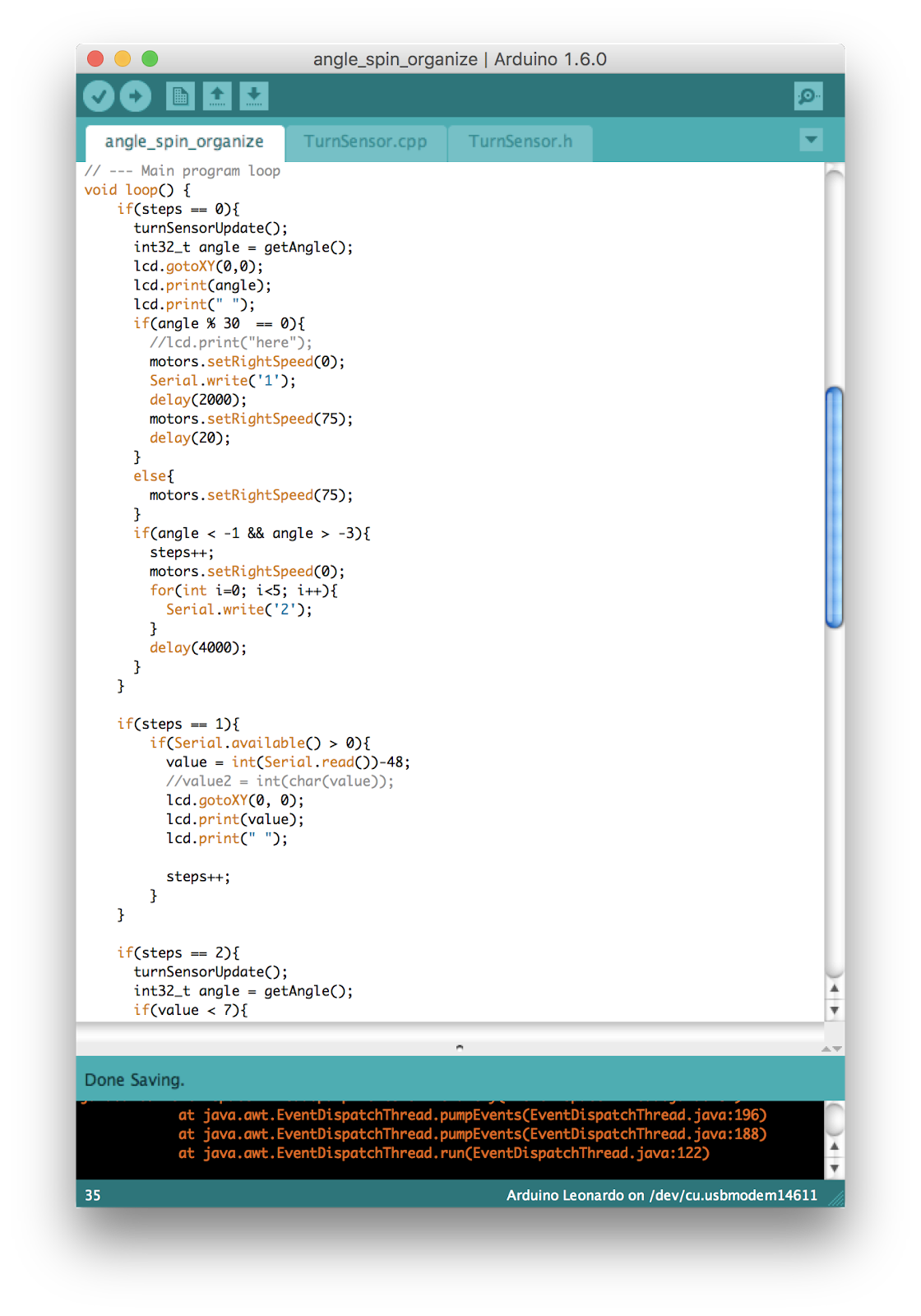
Process 2: Implementation
There are two players, the hider (a person) and the seeker (the robot) and they play the game in free space. The game of hide and seek runs for a maximum number of timesteps. Within the number of time steps, the hider will attempt to move past the robot and collect a reward (perhaps enter a certain location in the room, or collect an item the robot is guarding).
At each time step, the seeker will scan the room and capture images during the 360 degrees rotation. It will run a machine learning classification algorithm to identify faces from the captured images. Each image is serialised and is described by the angle at which the image was captured. When a face is identified, the robot chassis moves to the correct angle of orientation and forward in attempt to catch the hider. The process is repeated until the hider is successfully caught, or the hider wins.
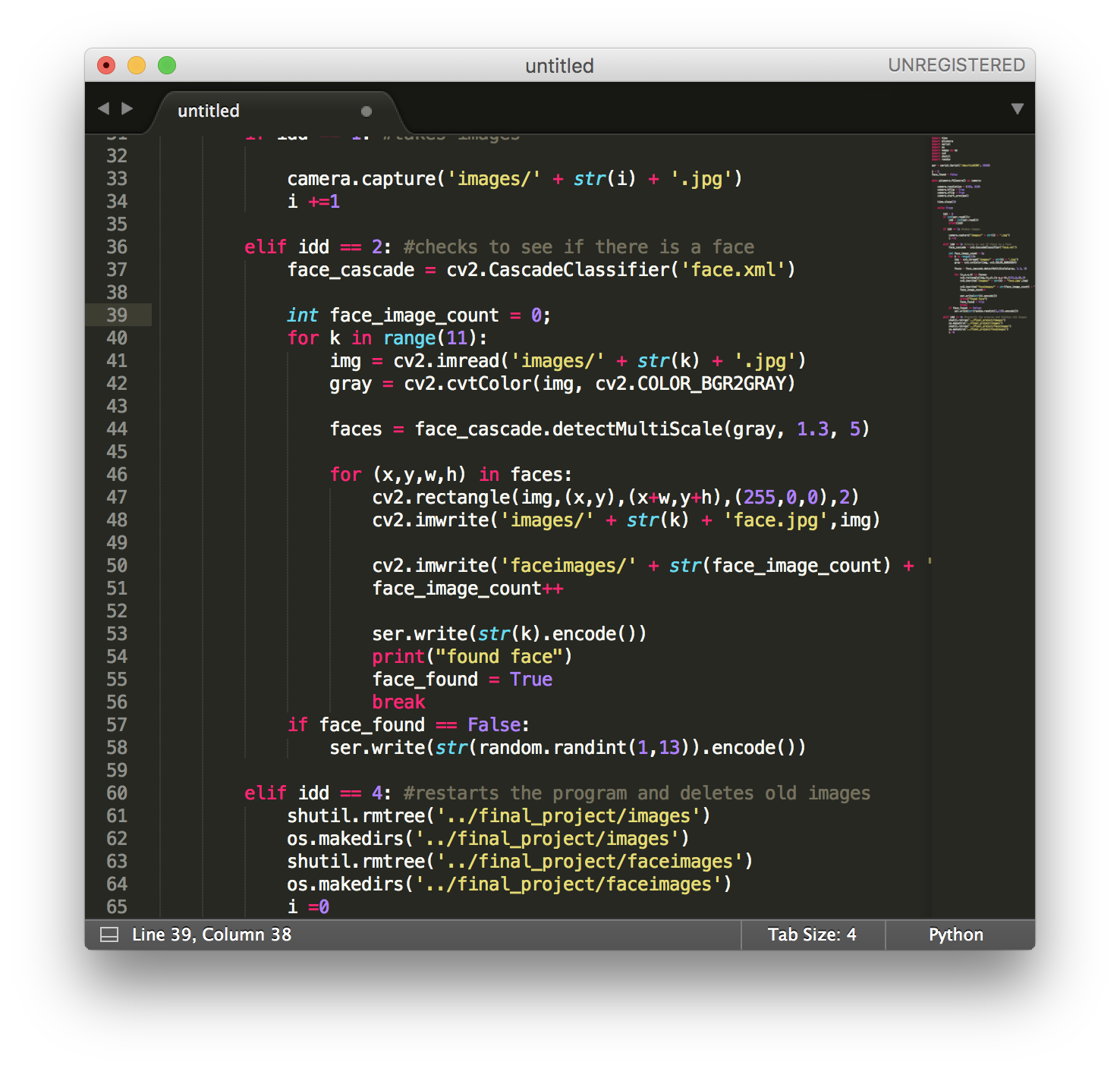
Process 3: Results
We anticipated that this experiment would give us important insights into the functionality of automates seeker methods used by a robot in real-world playing (interacting and predicting) against humans. We were able to successfully implement machine learning techniques by classifying faces from purely visual inputs.
However, we were unable to implement model-based reinforcement learning to enable to robot to make a strategic movement. Instead, we extracted the angle of image, gave it a serial number, and sent this to the arduino to move to the specific angle, then move forward for a given distance.
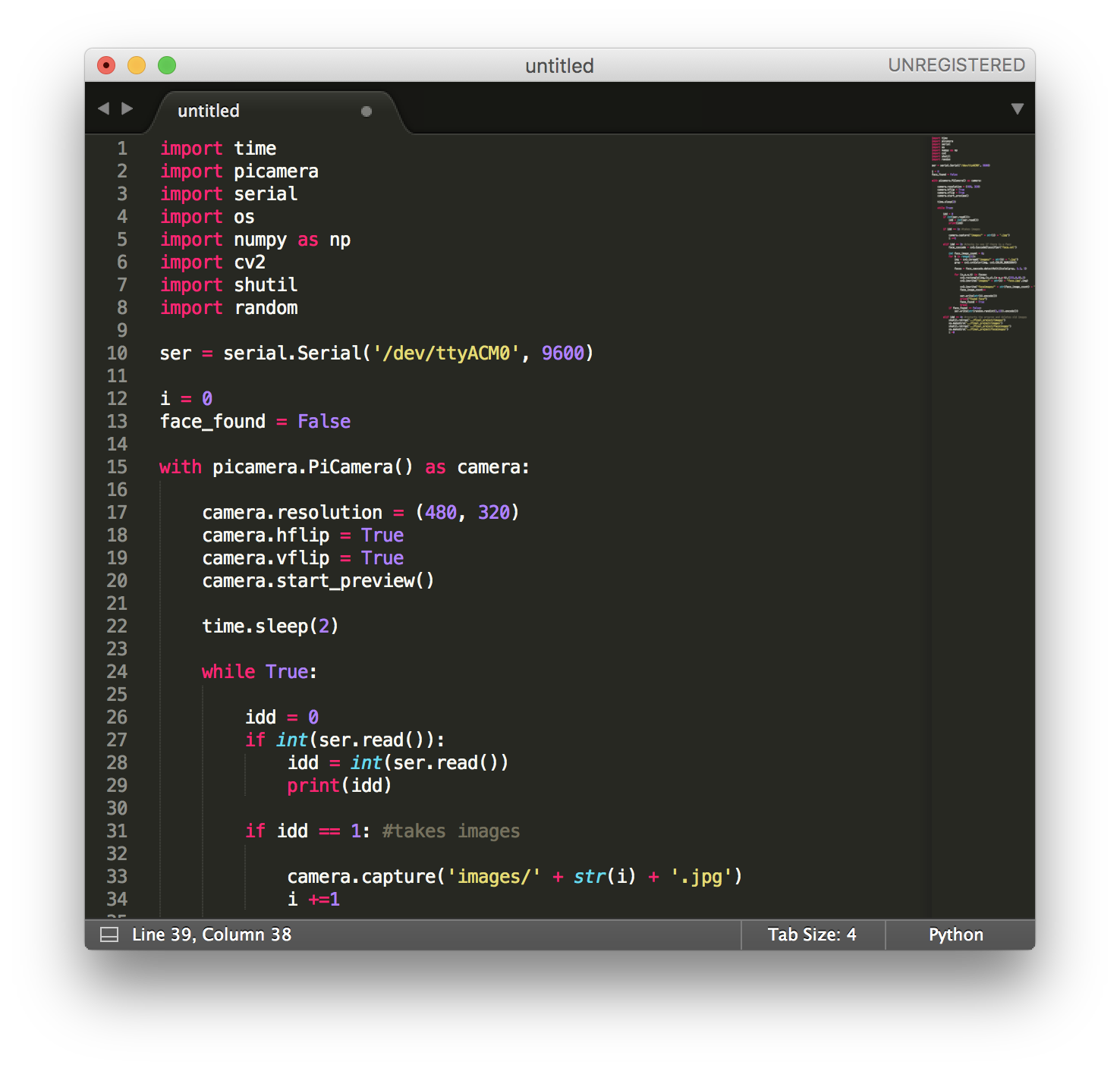
Process 4: Further Work
In the future, we would like to find a better way of implementing the Processing visual with the automated robotic ‘seeking’. Because the images took up large amount of working memory on the Pi, the 360 scan and the face identification processing time increased significantly after the first round of seeking. We were also planning to ‘stitch’ the panorama of images the robot took, and visually display this to the audience. However, the multiple image stitching programmes we found were difficult to implement with the Pi and did not work well with over 4 images in the dataset.
In addition, we would like to produce our own training data which identifies a ‘hider’ and a ‘base’. Using this training data, we can reward the ‘seeker’ when it completes a move that:
- Minimises the distance of the seeker from the hider
- Maximises the hider from the base
- The distance of the seeker from the base is less than the distance of the hider from the base
The code to run the visualisation locally is available on Github.
The project was exhibited at the Media Arts and Technology End of Year Show (MAT EYoS) in June 2018.